Homogen
är en Markov-kedja för vilken den villkorade sannolikheten för övergång från ett tillstånd  I en stat
I en stat  beror inte på testnumret. För homogena kedjor istället
beror inte på testnumret. För homogena kedjor istället  använd notationen
använd notationen  .
.
Ett exempel på en homogen Markov-kedja är slumpmässiga promenader. Låt det finnas en materialpartikel på linjen Ox i en punkt med heltalskoordinaten x=n. Vid vissa tider  partikeln ändrar sin position abrupt (till exempel kan den med sannolikhet p röra sig åt höger och med sannolikhet 1 –p– till vänster). Uppenbarligen beror koordinaten för partikeln efter hoppet på var partikeln var efter det omedelbart föregående hoppet, och beror inte på hur den rörde sig vid tidigare tidpunkter.
partikeln ändrar sin position abrupt (till exempel kan den med sannolikhet p röra sig åt höger och med sannolikhet 1 –p– till vänster). Uppenbarligen beror koordinaten för partikeln efter hoppet på var partikeln var efter det omedelbart föregående hoppet, och beror inte på hur den rörde sig vid tidigare tidpunkter.
I det följande kommer vi att begränsa oss till att överväga ändliga homogena Markov-kedjor.
Övergångssannolikheter. Övergångsmatris.
Övergångssannolikhet  kallas den betingade sannolikheten att från staten
kallas den betingade sannolikheten att från staten  Som ett resultat av nästa test kommer systemet att gå in i staten
Som ett resultat av nästa test kommer systemet att gå in i staten  . Alltså indexet
. Alltså indexet  relaterar till den föregående, och
relaterar till den föregående, och  - till det efterföljande tillståndet.
- till det efterföljande tillståndet.
Övergångsmatris system kallar en matris som innehåller alla övergångssannolikheter för detta system:
 , Var
, Var  representera övergångssannolikheterna i ett steg.
representera övergångssannolikheterna i ett steg.
Låt oss notera några funktioner i övergångsmatrisen.

Markov jämlikhet
Låt oss beteckna med  sannolikheten att systemet som ett resultat av n steg (tester) kommer att flytta sig från tillståndet
sannolikheten att systemet som ett resultat av n steg (tester) kommer att flytta sig från tillståndet  I en stat
I en stat  . Till exempel,
. Till exempel,  - sannolikheten för övergång i 10 steg från det tredje tillståndet till det sjätte. Observera att när n=1 reduceras denna sannolikhet helt enkelt till övergångssannolikheten
- sannolikheten för övergång i 10 steg från det tredje tillståndet till det sjätte. Observera att när n=1 reduceras denna sannolikhet helt enkelt till övergångssannolikheten  .
.
Frågan uppstår, hur, att känna till övergångssannolikheterna  , hitta sannolikheterna för tillståndsövergången
, hitta sannolikheterna för tillståndsövergången  I en stat
I en stat  steg för steg För detta ändamål, en mellanliggande (mellan
steg för steg För detta ändamål, en mellanliggande (mellan  Och
Och  ) skick. Med andra ord, man tror att från det ursprungliga tillståndet
) skick. Med andra ord, man tror att från det ursprungliga tillståndet  Efter m steg kommer systemet att övergå till ett mellantillstånd med sannolikhet
Efter m steg kommer systemet att övergå till ett mellantillstånd med sannolikhet  , varefter den i de återstående n–m stegen kommer att gå från det mellanliggande tillståndet till det slutliga tillståndet
, varefter den i de återstående n–m stegen kommer att gå från det mellanliggande tillståndet till det slutliga tillståndet  med sannolikhet
med sannolikhet  . Med hjälp av totalsannolikhetsformeln kan vi visa att formeln är giltig
. Med hjälp av totalsannolikhetsformeln kan vi visa att formeln är giltig 
Denna formel kallas Markov jämlikhet .
Att känna till alla övergångssannolikheter  , dvs. känna till övergångsmatrisen
, dvs. känna till övergångsmatrisen  från stat till stat i ett steg kan du hitta sannolikheterna
från stat till stat i ett steg kan du hitta sannolikheterna  övergång från tillstånd till tillstånd i två steg, och därför själva övergångsmatrisen
övergång från tillstånd till tillstånd i två steg, och därför själva övergångsmatrisen  , sedan - enligt den kända matrisen
, sedan - enligt den kända matrisen  - hitta
- hitta  etc.
etc.
Om vi sätter n= 2,m= 1 i Markov-likheten får vi faktiskt

eller  . I matrisform kan detta skrivas som
. I matrisform kan detta skrivas som  .
.
Om vi antar att n=3,m=2 får vi  . I det allmänna fallet är förhållandet sant
. I det allmänna fallet är förhållandet sant  .
.
Exempel. Låt övergången matris  lika med
lika med 
Vi måste hitta övergångsmatrisen  .
.
Multiplicera matris  på sig själv får vi
på sig själv får vi  .
.
För praktiska tillämpningar är frågan om att beräkna sannolikheten för att ett system är i ett visst tillstånd vid en specifik tidpunkt extremt viktig. Att lösa denna fråga kräver kunskap om de initiala förutsättningarna, d.v.s. sannolikheten för att systemet är i vissa tillstånd vid den initiala tiden. Den initiala sannolikhetsfördelningen för en Markov-kedja är sannolikhetsfördelningen av tillstånd i början av processen.
Här via  indikerar sannolikheten för att systemet är i tillståndet
indikerar sannolikheten för att systemet är i tillståndet  i det första ögonblicket. I det speciella fallet, om det initiala tillståndet för systemet är exakt känt (till exempel
i det första ögonblicket. I det speciella fallet, om det initiala tillståndet för systemet är exakt känt (till exempel  ), sedan den initiala sannolikheten
), sedan den initiala sannolikheten  , och alla andra är lika med noll.
, och alla andra är lika med noll.
Om den initiala sannolikhetsfördelningen och övergångsmatrisen ges för en homogen Markov-kedja, så anges sannolikheterna för systemet i det n:e steget  beräknas med den återkommande formeln
beräknas med den återkommande formeln
 .
.
För att illustrera, låt oss ge ett enkelt exempel. Låt oss överväga hur ett visst system fungerar (till exempel en enhet). Låt enheten vara i ett av två lägen under en dag - kan användas ( 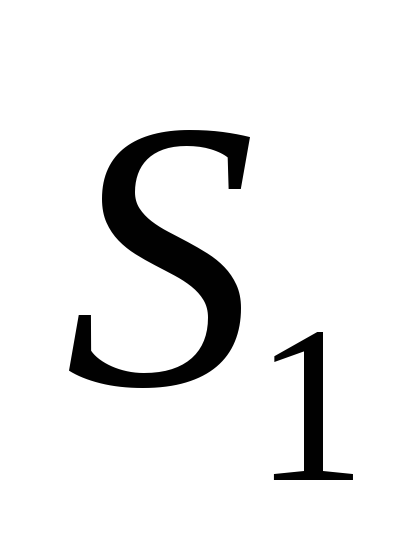 ) och felaktig (
) och felaktig (  ). Som ett resultat av massobservationer av anordningens funktion kompilerades följande övergångsmatris
). Som ett resultat av massobservationer av anordningens funktion kompilerades följande övergångsmatris  ,
,
Var  - sannolikheten att enheten förblir i gott skick;
- sannolikheten att enheten förblir i gott skick;
 - sannolikheten för att enheten övergår från ett funktionsdugligt till ett felaktigt tillstånd;
- sannolikheten för att enheten övergår från ett funktionsdugligt till ett felaktigt tillstånd;
 - sannolikheten för att enheten övergår från ett felaktigt till ett funktionsdugligt tillstånd;
- sannolikheten för att enheten övergår från ett felaktigt till ett funktionsdugligt tillstånd;
 - sannolikheten att enheten förblir i "defekt" tillstånd.
- sannolikheten att enheten förblir i "defekt" tillstånd.
Låt vektorn för initiala sannolikheter för enhetstillstånd ges av relationen
 , dvs.
, dvs.  (i det första ögonblicket var enheten felaktig). Det är nödvändigt att bestämma sannolikheterna för enhetens tillstånd efter tre dagar.
(i det första ögonblicket var enheten felaktig). Det är nödvändigt att bestämma sannolikheterna för enhetens tillstånd efter tre dagar.
Lösning: Med hjälp av övergångsmatrisen bestämmer vi sannolikheterna för tillstånd efter det första steget (efter den första dagen):
Sannolikheterna för tillstånd efter det andra steget (andra dagen) är lika
Slutligen är sannolikheterna för tillstånd efter det tredje steget (tredje dagen) lika
Sannolikheten för att enheten kommer att vara i gott skick är alltså 0,819 respektive 0,181 att den kommer att vara i felaktigt skick.
Markov process- en slumpmässig process som inträffar i systemet, som har egenskapen: för varje tidpunkt t 0 beror sannolikheten för något tillstånd i systemet i framtiden (vid t>t 0) endast på dess tillstånd i nuet (vid t = t 0) och beror inte på när och hur systemet kom till detta tillstånd (dvs hur processen utvecklades tidigare).
I praktiken möter vi ofta slumpmässiga processer som i olika grad av approximation kan betraktas som markoviska.
Varje Markov-process beskrivs med hjälp av tillståndssannolikheter och övergångssannolikheter.
Sannolikheter för tillstånd P k (t) för en Markov-processär sannolikheterna för att den slumpmässiga processen (systemet) vid tidpunkten t är i tillståndet S k:
Övergångssannolikheter för en Markov-processär sannolikheten för övergång av en process (system) från ett tillstånd till ett annat:
Markovprocessen kallas homogen, om övergångssannolikheterna per tidsenhet inte beror på var på tidsaxeln övergången sker.
Den enklaste processen är Markov kedja– Markov slumpmässig process med diskret tid och diskret ändlig uppsättning tillstånd.
När de analyseras är Markov-kedjorna tillståndsgraf, där alla tillstånd i kedjan (systemet) och sannolikheter som inte är noll är markerade i ett steg.
En Markov-kedja kan ses som om en punkt som representerar ett system rör sig slumpmässigt genom en tillståndsgraf, drar från tillstånd till tillstånd i ett steg eller stannar i samma tillstånd i flera steg.
Övergångssannolikheterna för en Markovkedja i ett steg skrivs i form av en matris P=||P ij ||, som kallas övergångssannolikhetsmatrisen eller helt enkelt övergångsmatrisen.
Exempel: uppsättningen av tillstånd för studenter i specialiteten är som följer:
S 1 – nybörjare;
S 2 – tvåan…;
S 5 – 5:e årsstudent;
S 6 – specialist som tog examen från ett universitet;
S 7 – en person som studerat vid ett universitet, men inte tagit examen.
Från tillstånd S 1 inom ett år är övergångar till tillstånd S 2 möjliga med sannolikhet r 1 ; S 1 med sannolikhet q 1 och S 7 med sannolikhet p 1, och:
r1+qi+pi=1.
Låt oss bygga en tillståndsgraf för denna Markov-kedja och markera den med övergångssannolikheter (ej noll).
Låt oss skapa en matris med övergångssannolikheter:
Övergångsmatriser har följande egenskaper:
Alla deras element är icke-negativa;
Deras radsummor är lika med en.
Matriser med denna egenskap kallas stokastiska.
Övergångsmatriser låter dig beräkna sannolikheten för vilken Markov-kedja som helst med hjälp avn.
För homogena Markov-kedjor är övergångsmatriser inte beroende av tid.
När man studerar Markov-kedjor är de som är mest intressanta:
Sannolikheter för övergång i m steg;
Fördelning över tillstånd i steg m→∞;
Genomsnittlig tid tillbringad i ett visst tillstånd;
Genomsnittlig tid för att återgå till detta tillstånd.
Betrakta en homogen Markov-kedja med n tillstånd. För att erhålla sannolikheten för övergång från tillstånd Si till tillstånd Sj i m steg, i enlighet med totalsannolikhetsformeln, bör man summera produkterna av sannolikheten för övergång från tillstånd Si till det mellanliggande tillståndet Sk i l steg med sannolikheten av övergång från Sk till Sj i de återstående m-l stegen, d.v.s.
Denna relation är för alla i=1, …, n; j=1, …,n kan representeras som en produkt av matriser:
P(m)=P(l)*P(ml).
Så vi har:
P(2)=P(1)*P(1)=P2
P(3)=P(2)*P(1)=P(1)*P(2)=P3, etc.
P(m)=P(m-1)*P(1)=P(1)*P(M-1)=Pm,
vilket gör det möjligt att hitta sannolikheterna för övergång mellan tillstånd i valfritt antal steg, att känna till övergångsmatrisen i ett steg, nämligen P ij (m) - ett element i matrisen P(m) är sannolikheten att flytta från tillstånd S i att ange S j i m steg.
Exempel: Vädret i en viss region växlar mellan regnigt och torrt under långa tidsperioder. Om det regnar, så kommer det med sannolikhet 0,7 att regna nästa dag; Om vädret är torrt en viss dag, kommer det med en sannolikhet på 0,6 att bestå nästa dag. Det är känt att vädret var regnigt på onsdagen. Hur stor är sannolikheten att det blir regn nästa fredag?
Låt oss skriva ner alla tillstånd i Markov-kedjan i detta problem: D – regnigt väder, C – torrt väder.
Låt oss bygga en tillståndsgraf:
Svar: p 11 = p (D häl | D avg) = 0,61.
Sannolikhetsgränserna р 1 (m), р 2 (m),..., р n (m) för m→∞, om de finns, kallas begränsande sannolikheter för stater.
Följande teorem kan bevisas: om man i en Markov-kedja kan gå från + varje tillstånd (i ett givet antal steg) till varandra, så existerar tillståndens begränsande sannolikheter och beror inte på systemets initiala tillstånd .
Sålunda, som m→∞, etableras en viss begränsande stationär regim i systemet, där vart och ett av tillstånden inträffar med en viss konstant sannolikhet.
Vektorn p, sammansatt av marginella sannolikheter, måste uppfylla förhållandet: p=p*P.
Genomsnittlig tid tillbringad i staten Si för tiden T är lika med p i *T, där p i - marginell sannolikhet för tillstånd S i . Genomsnittlig tid att återgå till staten S i är lika med .
Exempel.
För många ekonomiska problem är det nödvändigt att känna till årens växling med vissa värden för årliga flodflöden. Naturligtvis kan denna växling inte bestämmas helt exakt. För att bestämma sannolikheterna för växling (övergång) delar vi flödena genom att introducera fyra graderingar (systemets tillstånd): första (lägsta flöde), andra, tredje, fjärde (högsta flödet). För visshetens skull kommer vi att anta att den första graderingen aldrig följs av den fjärde och den fjärde av den första på grund av ackumulering av fukt (i marken, reservoaren, etc.). Observationer har visat att i en viss region är andra övergångar möjliga, och:
a) från den första graderingen kan du flytta till var och en av de mellersta dubbelt så ofta som igen till den första, d.v.s.
p 11 = 0,2; p12 = 0,4; p13 = 0,4; p 14 = 0;
b) från den fjärde graderingen sker övergångar till andra och tredje graderingen fyra och fem gånger oftare än returer som i den andra, d.v.s.
hårt, d.v.s.
i den fjärde, dvs.
p 41 = 0; p 42 = 0,4; p 43 = 0,5; p 44 = 0,1;
c) från den andra till andra graderingar kan bara vara mindre frekventa: i den första - två gånger mindre, i den tredje med 25%, i den fjärde - fyra gånger mindre ofta än övergången till den andra, d.v.s.
p21=0,2;p22=0,4; p23 = 0,3; p 24 = 0,1;
d) från den tredje graderingen är en övergång till den andra graderingen lika sannolik som en återgång till den tredje graderingen, och övergångar till den första och fjärde graderingen är fyra gånger mindre sannolika, dvs.
p31 = 0,1; p32 = 0,4; p 33 = 0,4; p 34 = 0,1;
Låt oss bygga en graf:
Låt oss skapa en matris med övergångssannolikheter:
Låt oss ta reda på den genomsnittliga tiden mellan torka och högvattenår. För att göra detta måste du hitta gränsfördelningen. Det finns pga villkoret för satsen är uppfyllt (matrisen P2 innehåller inte nollelement, d.v.s. i två steg kan du gå från vilket som helst tillstånd i systemet till vilket som helst annat).
där p4 = 0,08; p 3 =; p 2 =; p1 = 0,15
Frekvensen för återgång till tillstånd Si är lika med .
Följaktligen är frekvensen av torra år i genomsnitt 6,85, d.v.s. 6-7 år och regniga år 12.
Markov-kedjor
Introduktion
§ 1. Markovkedja
§ 2. Homogen Markov-kedja. Övergångssannolikheter. Övergångsmatris
§3. Markov jämlikhet
§4. Stationär distribution. Limit Probability Theorem
§5. Bevis för satsen om begränsning av sannolikheter i en Markov-kedja
§6. Tillämpningar av Markov-kedjor
Slutsats
Lista över begagnad litteratur
Introduktion
Ämnet för vårt kursarbete är Markov-kedjan. Markov-kedjor är uppkallade efter den enastående ryske matematikern Andrei Andreevich Markov, som arbetade mycket med slumpmässiga processer och gjorde ett stort bidrag till utvecklingen av detta område. Nyligen kan du höra om användningen av Markov-kedjor inom en mängd olika områden: modern webbteknologi, när du analyserar litterära texter eller till och med när du utvecklar taktik för ett fotbollslag. De som inte vet vad Markov-kedjor är kan ha en känsla av att det är något väldigt komplext och nästan obegripligt.
Nej, det är precis tvärtom. En Markov-kedja är ett av de enklaste fallen av en sekvens av slumpmässiga händelser. Men trots sin enkelhet kan den ofta vara användbar även när man beskriver ganska komplexa fenomen. En Markov-kedja är en sekvens av slumpmässiga händelser där sannolikheten för varje händelse endast beror på den föregående, men inte beror på tidigare händelser.
Innan vi går djupare måste vi överväga några hjälpfrågor som är allmänt kända, men som är absolut nödvändiga för vidare utläggning.
Målet med mitt kursarbete är att närmare studera Markov-kedjors tillämpningar, problemformulering och Markovproblem.
§1. Markov kedja
Låt oss föreställa oss att en sekvens av tester utförs.
Definition. En Markov-kedja är en sekvens av försök i var och en av vilka en och endast en av de inkompatibla händelserna i hela gruppen uppträder, och den villkorade sannolikheten för att händelsen inträffar i den :e försöket är ![]() , förutsatt att händelsen inträffade under den e rättegången
, förutsatt att händelsen inträffade under den e rättegången ![]() , beror inte på resultaten från tidigare tester.
, beror inte på resultaten från tidigare tester.
Till exempel, om sekvensen av försök bildar en Markov-kedja och hela gruppen består av fyra inkompatibla händelser, och det är känt att händelsen inträffade i det sjätte försöket, beror inte den villkorade sannolikheten för att händelsen inträffar i den sjunde försöket på vilka händelser som dök upp i det första, andra, ..., femte testet.
Observera att oberoende tester är ett specialfall av en Markov-kedja. Faktum är att om testerna är oberoende, beror förekomsten av en viss händelse i något test inte på resultaten av tidigare utförda tester. Härav följer att begreppet en Markovkedja är en generalisering av begreppet oberoende prövningar.
Ofta, när de presenterar teorin om Markov-kedjor, ansluter de sig till en annan terminologi och talar om ett visst fysiskt system, som vid varje tidpunkt är i ett av tillstånden: , och ändrar sitt tillstånd endast vid separata ögonblick, att är att systemet flyttar från ett tillstånd till ett annat (till exempel från till ). För Markov-kedjor är sannolikheten att gå till vilken stat som helst ![]() för tillfället beror bara på vilket tillstånd systemet var i för tillfället, och ändras inte eftersom dess tillstånd vid tidigare ögonblick blir kända. Också, i synnerhet, efter testet kan systemet förbli i samma tillstånd ("flytta" från stat till stat).
för tillfället beror bara på vilket tillstånd systemet var i för tillfället, och ändras inte eftersom dess tillstånd vid tidigare ögonblick blir kända. Också, i synnerhet, efter testet kan systemet förbli i samma tillstånd ("flytta" från stat till stat).
För att illustrera, överväg ett exempel.
Exempel 1. Låt oss föreställa oss att en partikel som ligger på en rät linje rör sig längs denna räta linje under påverkan av slumpmässiga stötar som inträffar i ögonblick . En partikel kan lokaliseras vid punkter med heltalskoordinater: ![]() ; De reflekterande väggarna är placerade vid punkterna. Varje tryck flyttar partikeln till höger med sannolikhet och till vänster med sannolikhet, om inte partikeln är nära en vägg. Om partikeln är nära väggen, flyttar varje tryck den en enhet innanför gapet mellan väggarna. Här ser vi att detta exempel på en partikelvandring är en typisk Markovkedja.
; De reflekterande väggarna är placerade vid punkterna. Varje tryck flyttar partikeln till höger med sannolikhet och till vänster med sannolikhet, om inte partikeln är nära en vägg. Om partikeln är nära väggen, flyttar varje tryck den en enhet innanför gapet mellan väggarna. Här ser vi att detta exempel på en partikelvandring är en typisk Markovkedja.
Sålunda kallas händelser för systemets tillstånd, och tester kallas förändringar i dess tillstånd.
Låt oss nu definiera en Markov-kedja med hjälp av ny terminologi.
En tidsdiskret Markov-kedja är en krets vars tillstånd ändras vid vissa bestämda tidpunkter.
En kontinuerlig Markov-kedja är en kedja vars tillstånd ändras vid alla slumpmässiga möjliga ögonblick i tiden.
§2. Homogen Markov-kedja. Övergångssannolikheter. Övergångsmatris
Definition. En Markovkedja kallas homogen om den villkorade sannolikheten (övergång från tillstånd till tillstånd) inte beror på försöksnumret. Därför istället för att skriva helt enkelt .
Exempel 1. En spontan promenad. Låt det finnas en materialpartikel på en rät linje i en punkt med en heltalskoordinat. Vid vissa tidpunkter upplever partikeln stötar. Under påverkan av ett tryck rör sig partikeln med sannolikhet en enhet till höger och med sannolikhet en enhet till vänster. Det är tydligt att positionen (koordinaten) för en partikel efter en stöt beror på var partikeln befann sig efter den omedelbart föregående stöten, och inte beror på hur den rörde sig under påverkan av andra tidigare stötar.
Således är en slumpmässig promenad ett exempel på en homogen Markov-kedja med diskret tid.
Övergångssannolikheten är den villkorade sannolikheten att från det tillstånd (i vilket systemet befann sig som ett resultat av något test, oavsett vilket nummer) som ett resultat av nästa test kommer systemet att flytta till tillståndet.
Sålunda, i beteckningen, indikerar det första indexet numret för det föregående tillståndet, och det andra indikerar numret för det efterföljande tillståndet. Till exempel är sannolikheten för övergång från det andra tillståndet till det tredje.
Låt antalet stater vara ändliga och lika med .
Övergångsmatrisen för ett system är en matris som innehåller alla övergångssannolikheter för detta system:

Eftersom varje rad i matrisen innehåller sannolikheterna för händelser (övergång från samma tillstånd till alla möjliga tillstånd) som bildar en komplett grupp, är summan av sannolikheterna för dessa händelser lika med en. Med andra ord är summan av övergångssannolikheterna för varje rad i övergångsmatrisen lika med en:
Låt oss ge ett exempel på övergångsmatrisen för ett system som kan vara i tre tillstånd; övergången från stat till stat sker enligt schemat för en homogen Markov-kedja; övergångssannolikheter ges av matrisen:

Här ser vi att om systemet var i tillstånd, då efter att ha ändrat tillståndet i ett steg, kommer det att förbli i samma tillstånd med sannolikhet 0,5, förbli i samma tillstånd med sannolikhet 0,5, kommer att gå in i tillstånd med sannolikhet 0,2, sedan efter övergången kan det hamna i stater; den kan inte flytta från stat till. Den sista raden i matrisen visar oss att från ett tillstånd att gå till något av de möjliga tillstånden med samma sannolikhet på 0,1.
Baserat på systemets övergångsmatris kan du bygga en så kallad tillståndsgraf av systemet, den kallas även en märkt tillståndsgraf. Detta är bekvämt för en visuell representation av kretsen. Låt oss titta på ordningen för att konstruera grafer med hjälp av ett exempel.
Exempel 2. Använd en given övergångsmatris, konstruera en tillståndsgraf.

Därför att matris av fjärde ordningen, så har systemet följaktligen 4 möjliga tillstånd.

Grafen visar inte sannolikheterna för att systemet övergår från ett tillstånd till samma. När man överväger specifika system är det bekvämt att först konstruera en tillståndsgraf och sedan bestämma sannolikheten för övergångar av systemet från ett tillstånd till detsamma (baserat på kravet att summan av elementen i matrisens rader är lika med en), och konstruera sedan en övergångsmatris för systemet.
§3. Markov jämlikhet
Definition. Låt oss beteckna med sannolikheten att som ett resultat av steg (tester) kommer systemet att flytta från tillstånd till tillstånd. Till exempel är sannolikheten för övergång i 10 steg från det andra tillståndet till det femte.
Vi betonar att vi får övergångssannolikheterna
Låt oss sätta oss en uppgift: att känna till övergångssannolikheterna, hitta sannolikheterna för att systemet övergår från tillstånd till tillstånd i steg.
För detta ändamål inför vi ett mellantillstånd (mellan och ). Med andra ord kommer vi att anta att systemet från det initiala tillståndet i steg kommer att gå över till ett mellantillstånd med sannolikhet , varefter det i de återstående stegen från det mellanliggande tillståndet med sannolikhet kommer att gå till sluttillståndet .
Med hjälp av den totala sannolikhetsformeln får vi
![]() . (1)
. (1)
Denna formel kallas Markovs jämlikhet.
Förklaring. Låt oss presentera följande notation:
– händelsen vi är intresserade av (i steg kommer systemet att gå från initialtillstånd till sluttillstånd), därför, ; ![]() − hypoteser (i steg kommer systemet att flytta från det initiala tillståndet till det mellanliggande tillståndet), därför, − villkorad sannolikhet för förekomst, förutsatt att hypotesen ägde rum (i steg kommer systemet att flytta från det mellanliggande tillståndet till det slutliga tillståndet), därför,
− hypoteser (i steg kommer systemet att flytta från det initiala tillståndet till det mellanliggande tillståndet), därför, − villkorad sannolikhet för förekomst, förutsatt att hypotesen ägde rum (i steg kommer systemet att flytta från det mellanliggande tillståndet till det slutliga tillståndet), därför, ![]()
Enligt formeln för total sannolikhet,
![]() ()
()
Eller i den notation vi har antagit
![]()
som sammanfaller med Markovs formel (1).
Genom att känna till alla övergångssannolikheter, det vill säga att känna till övergångsmatrisen från tillstånd till tillstånd i ett steg, kan du hitta sannolikheterna för övergång från tillstånd till tillstånd i två steg, och därför själva övergångsmatrisen; med hjälp av en känd matris kan du hitta övergångsmatrisen från tillstånd till tillstånd i tre steg osv.
Faktum är att lägga in Markov-jämlikheten
![]() ,
,
kedja av märken slumpmässig sannolikhet
![]() ,
,
![]() (2)
(2)
Med hjälp av formel (2) kan du alltså hitta alla sannolikheter och därför själva matrisen. Eftersom direkt användning av formel (2) visar sig vara tråkig, och matriskalkyl leder till målet snabbare, kommer jag att skriva relationerna som härrör från (2) i matrisform:
![]()
Om vi lägger in (1) får vi på liknande sätt
![]()
I allmänhet
Sats 1. För alla s, t
![]() (3)
(3)
Bevis. Låt oss beräkna sannolikheten ![]() med hjälp av den totala sannolikhetsformeln (), putting
med hjälp av den totala sannolikhetsformeln (), putting
Från jämställdhet
Därav från jämställdhet (4) och
vi får påståendet om satsen.
Låt oss definiera matrisen I matris har notation (3) formen
Sedan dess var är övergångssannolikhetsmatrisen. Av (5) följer
![]() (6)
(6)
Resultaten som erhålls i teorin om matriser gör det möjligt att använda formel (6) för att beräkna och studera deras beteende när
Exempel 1.Övergångsmatris specificerad ![]() Hitta övergångsmatrisen
Hitta övergångsmatrisen ![]()
Lösning. Låt oss använda formeln
Multiplicerar vi matriserna får vi slutligen:
![]() .
.
§4. Stationär distribution. Limit Probability Theorem
Sannolikhetsfördelningen vid en godtycklig tidpunkt kan hittas med den totala sannolikhetsformeln
![]() (7)
(7)
Det kan visa sig att det inte beror på tid. Låt oss ringa stationär distribution vektor ![]() , som uppfyller villkoren
, som uppfyller villkoren
var är övergångssannolikheterna.
Om i en Markov-kedja ![]() sedan för någon
sedan för någon
![]()
Detta uttalande följer av induktion från (7) och (8).
Låt oss presentera formuleringen av teoremet om begränsning av sannolikheter för en viktig klass av Markov-kedjor.
Sats 1. Om för några >0 alla element i matrisen är positiva, då för alla , för
![]() , (9)
, (9)
Var ![]() stationär fördelning med en viss konstant som uppfyller olikheten 0<
h
<1.
stationär fördelning med en viss konstant som uppfyller olikheten 0<
h
<1.
Eftersom , då enligt villkoren för teoremet, från vilket tillstånd som helst kan du komma till vilket tillstånd som helst i tid med en positiv sannolikhet. Villkoren för satsen utesluter kedjor som i någon mening är periodiska.
Om villkoren för sats 1 är uppfyllda, beror sannolikheten för att systemet är i ett visst tillstånd i gränsen inte på den initiala fördelningen. Av (9) och (7) följer faktiskt att för varje initial distribution,
![]()
Låt oss överväga flera exempel på Markov-kedjor för vilka villkoren i sats 1 inte är uppfyllda. Det är inte svårt att verifiera att sådana exempel är exempel. I exemplet har övergångssannolikheterna gränser, men dessa gränser beror på initialtillståndet. I synnerhet när
![]()
I andra exempel existerar uppenbarligen inte sannolikhetsintervallen för.
Låt oss hitta den stationära fördelningen i exempel 1. Vi måste hitta vektorn ![]() uppfylla villkor (8):
uppfylla villkor (8):
![]() ,
,
![]() ;
;
![]()
Därför existerar alltså en stationär fördelning, men inte alla koordinatvektorer är positiva.
För polynomschemat introducerades slumpvariabler lika med antalet utfall av en given typ. Låt oss introducera liknande kvantiteter för Markov-kedjor. Låt vara antalet gånger som systemet går in i tillståndet i tid. Sedan frekvensen av systemet som träffar staten. Med hjälp av formler (9) kan vi bevisa att när närmar sig . För att göra detta måste du få asymptotiska formler för och och använda Chebyshevs ojämlikhet. Här är härledningen av formeln för . Låt oss representera det i formen
![]() (10)
(10)
var, om och annars. Därför att
![]() ,
,
sedan, med hjälp av egenskapen matematisk förväntan och formel (9), får vi
![]() .
.
I kraft av sats 1 är trippeltermen på höger sida av denna likhet en delsumma av en konvergent serie. Att sätta ![]() , vi får
, vi får
Eftersom den
![]()
Särskilt av formel (11) följer det
![]() på
på
Du kan också få en formel som används för att beräkna variansen.
§5. Bevis för satsen om begränsning av sannolikheter i en Markov-kedja
Låt oss först bevisa två lemman. Låt oss sätta
![]()
![]()
Lemma 1. Det finns gränser för alla
Bevis. Med hjälp av ekvation (3) får vi
Således är sekvenserna både monotona och begränsade. Detta innebär uttalandet av Lemma 1.
Lemma 2.
Om villkoren för sats 2 är uppfyllda, så finns det konstanter, ![]() Så att
Så att
För alla
![]()
![]()
där , betyder summering över allt för vilket är positivt, och summering över resten . Härifrån
![]() . (12)
. (12)
Eftersom under villkoren i sats 1 övergångssannolikheterna för alla , då för alla
Och på grund av det ändliga antalet tillstånd
Låt oss nu uppskatta skillnaden ![]() . Genom att använda ekvation (3) med , , får vi
. Genom att använda ekvation (3) med , , får vi
Härifrån hittar vi med hjälp av (8)-(10).
=![]() .
.
Genom att kombinera detta förhållande med ojämlikhet (14), får vi uttalandet om lemma.
Gå till beviset för satsen. Eftersom sekvenserna är monotona alltså
0<![]() . (15)
. (15)
Ur denna och Lemma 1 finner vi
Därför, när du får och
Positivitet följer av ojämlikhet (15). Om vi passerar till gränsen vid och i ekvation (3), får vi som uppfyller ekvation (12). Teoremet har bevisats.
§6. Tillämpningar av Markov-kedjor
Markov-kedjor fungerar som en bra introduktion till teorin om slumpmässiga processer, d.v.s. teorin om enkla sekvenser av en familj av slumpvariabler, vanligtvis beroende på en parameter, som i de flesta tillämpningar spelar rollen som tid. Den är främst avsedd att fullständigt beskriva både långsiktigt och lokalt beteende hos en process. Här är några av de mest studerade frågorna i detta avseende.
Brownsk rörelse och dess generaliseringar - diffusionsprocesser och processer med oberoende inkrement . Teorin om slumpmässiga processer bidrog till en fördjupning av sambandet mellan sannolikhetsteorin, teorin om operatorer och teorin om differentialekvationer, vilket bland annat var viktigt för fysik och andra tillämpningar. Tillämpningar inkluderar processer av intresse för försäkringsmatematik, köteori, genetik, trafikkontroll, elektrisk kretsteori och inventeringsteori.
Martingales . Dessa processer bevarar tillräckligt många egenskaper hos Markov-kedjorna för att viktiga ergodiska satser förblir giltiga för dem. Martingales skiljer sig från Markov-kedjor genom att när det nuvarande tillståndet är känt, beror bara den matematiska förväntningen på framtiden, men inte nödvändigtvis själva sannolikhetsfördelningen, på det förflutna. Martingalteorin har förutom att vara ett viktigt forskningsverktyg berikat teorin om slumpmässiga processer som uppstår i statistik, kärnklyvningsteori, genetik och informationsteori med nya gränssatser.
Stationära processer . Den äldsta kända ergodiska satsen, som noterats ovan, kan tolkas som ett resultat som beskriver det begränsande beteendet hos en stationär slumpmässig process. En sådan process har egenskapen att alla probabilistiska lagar som den uppfyller förblir oföränderliga med avseende på tidsförskjutningar. Den ergodiska satsen, som först formulerades av fysiker som en hypotes, kan representeras som ett påstående om att ensemblemedelvärdet under vissa förhållanden sammanfaller med tidsgenomsnittet. Detta innebär att samma information kan erhållas från långtidsobservation av ett system och från samtidig (och momentan) observation av många oberoende kopior av samma system. Lagen om stora tal är inget annat än ett specialfall av Birkhoffs ergodiska sats. Interpolation och förutsägelse av beteendet hos stationära Gaussiska processer, tolkade i vid mening, tjänar som en viktig generalisering av klassisk teori om minsta kvadrater. Teorin om stationära processer är ett nödvändigt forskningsverktyg inom många områden, till exempel inom kommunikationsteori, som handlar om att studera och skapa system som sänder meddelanden i närvaro av brus eller slumpmässiga störningar.
Markov-processer (processer utan efterverkningar) spelar en stor roll i modellering av kösystem (QS), samt vid modellering och val av strategi för att hantera socioekonomiska processer som förekommer i samhället.
Markov-kedjan kan också användas för att generera texter. Flera texter levereras som indata, sedan byggs en Markov-kedja med sannolikheterna för ett ord efter det andra, och den resulterande texten skapas utifrån denna kedja. Leksaken visar sig vara väldigt underhållande!
Slutsats
I vårt kursarbete talade vi alltså om Markov-kedjekretsen. Vi lärde oss inom vilka områden och hur den används, oberoende tester bevisade satsen om att begränsa sannolikheter i en Markov-kedja, gav exempel på en typisk och homogen Markov-kedja, samt för att hitta övergångsmatrisen.
Vi har sett att Markov-kedjans design är en direkt generalisering av den oberoende testdesignen.
Lista över begagnad litteratur
1. Chistyakov V.P. Sannolikhetslära kurs. 6:e uppl., rev. − St. Petersburg: Lan Publishing House, 2003. − 272 sid. − (Lärobok för universitet. Speciallitteratur).
2. Gnedenko B.V. Sannolikhetslära kurs.
3. Gmurman V.E. Sannolikhetsteori och matematisk statistik.
4. Ventzel E.S. Sannolikhetsteori och dess tekniska tillämpningar.
5. Kolmogorov A.N., Zhurbenko I.G., Prokhorov A.V. Introduktion till sannolikhetsteori. − Moskva-Izhevsk: Institutet för datorforskning, 2003, 188 s.
6. Katz M. Sannolikhet och relaterade frågor i fysik.
Markov kedja- en händelsekedja där sannolikheten för varje händelse endast beror på det tidigare tillståndet.
Denna artikel är av abstrakt karaktär, skriven på grundval av de källor som ges i slutet, som citeras på sina ställen.
Introduktion till teorin om Markov-kedjor
En Markov-kedja är en sekvens av slumpmässiga händelser där sannolikheten för varje händelse endast beror på det tillstånd där processen för närvarande befinner sig och inte beror på tidigare tillstånd. Den slutliga diskreta kretsen bestäms av:
∑ j=1…n p ij = 1
Ett exempel på en matris av övergångssannolikheter med en uppsättning tillstånd S = (S 1, ..., S 5), en vektor med initiala sannolikheter p (0) = (1, 0, 0, 0, 0):
MED  Med hjälp av vektorn för initiala sannolikheter och övergångsmatrisen kan vi beräkna den stokastiska vektorn p (n) - en vektor sammansatt av sannolikheterna p (n) (i) att processen kommer att vara i tillstånd i vid tidpunkten n. Du kan få p(n) med formeln:
Med hjälp av vektorn för initiala sannolikheter och övergångsmatrisen kan vi beräkna den stokastiska vektorn p (n) - en vektor sammansatt av sannolikheterna p (n) (i) att processen kommer att vara i tillstånd i vid tidpunkten n. Du kan få p(n) med formeln:
p(n) = p(0)×Pn
Vektorer p (n) när n växer stabiliseras i vissa fall - de konvergerar till en viss sannolikhetsvektor ρ, som kan kallas den stationära fördelningen av kedjan. Stationaritet manifesteras i det faktum att med p (0) = ρ får vi p (n) = ρ för vilket n som helst.
Det enklaste kriteriet som garanterar konvergens till en stationär fördelning är som följer: om alla element i övergångssannolikhetsmatrisen P är positiva, då tenderar n till oändligheten, tenderar vektorn p (n) till vektorn ρ, vilket är den enda lösningen till formulärets system
Det kan också visas att om, för något positivt värde på n, alla element i matrisen Pn är positiva, så kommer vektorn p(n) fortfarande att stabiliseras.
Beviset för dessa uttalanden tillhandahålls i detalj.
En Markov-kedja avbildas som en övergångsgraf, vars hörn motsvarar kedjans tillstånd, och bågarna motsvarar övergångar mellan dem. Vikten av bågen (i, j) som förbinder hörnen si och sj kommer att vara lika med sannolikheten pi(j) för övergång från det första tillståndet till det andra. Graf som motsvarar matrisen som visas ovan:
TILL  klassificering av delstater i Markov-kedjor
klassificering av delstater i Markov-kedjor
När vi överväger Markov-kedjor kan vi vara intresserade av systemets beteende under en kort tidsperiod. I det här fallet beräknas absoluta sannolikheter med formlerna från föregående avsnitt. Det är dock viktigare att studera systemets beteende över ett långt tidsintervall, när antalet övergångar tenderar till oändlighet. Därefter introduceras definitioner av tillstånden i Markov-kedjorna, som är nödvändiga för att studera systemets beteende på lång sikt.
Markov-kedjor klassificeras beroende på möjligheten till övergång från ett tillstånd till ett annat.
Grupper av tillstånd i en Markov-kedja (delmängder av hörn i övergångsgrafen), som motsvarar återvändspunkter i övergångsdiagrammets ordningsdiagram, kallas ergotiska klasser av kedjan. Om vi betraktar grafen som visas ovan kan vi se att den innehåller 1 ergodisk klass M1 = (S5), nåbar från en starkt ansluten komponent som motsvarar en delmängd av hörn M2 = (S1, S2, S3, S4). Stater som är i ergodiska klasser kallas väsentliga, och resten kallas icke-väsentliga (även om sådana namn inte stämmer väl överens med sunt förnuft). Det absorberande tillståndet si är ett specialfall av den ergotiska klassen. Sedan, en gång i ett sådant tillstånd, kommer processen att stoppa. För Si kommer pii = 1 att vara sant, dvs. i övergångsgrafen kommer endast en kant att utgå från den - en slinga.
Absorberande Markov-kedjor används som tillfälliga modeller av program och beräkningsprocesser. Vid modellering av ett program identifieras kretsens tillstånd med programmets block, och matrisen av övergångssannolikheter bestämmer ordningen för övergångar mellan block, beroende på programmets struktur och fördelningen av initiala data, värdena som påverkar utvecklingen av beräkningsprocessen. Som ett resultat av att representera programmet med en absorberande krets är det möjligt att beräkna antalet åtkomster till programblock och programexekveringstiden, uppskattad av medelvärden, varianser och, om nödvändigt, fördelningar. Genom att använda denna statistik i framtiden kan du optimera programkoden - använd lågnivåmetoder för att snabba upp kritiska delar av programmet. Denna metod kallas kodprofilering.
Till exempel, i Dijkstras algoritm finns följande kretstillstånd:
vertex (v), extrahera ett nytt vertex från prioritetskön, gå till endast tillstånd b;
börja (b), början av cykeln för att söka utgående bågar för försvagningsproceduren;
analys (a), analys av nästa båge, möjlig övergång till a, d eller e;
minska (d), minska skattningen för en del av grafens hörn, flytta till a;
slut (e), slutförande av slingan, flytta till nästa vertex.
Det återstår att ställa in sannolikheterna för övergången mellan hörn, och du kan studera varaktigheten av övergångar mellan hörn, sannolikheterna för att komma in i olika tillstånd och andra genomsnittliga egenskaper hos processen.
På liknande sätt kan beräkningsprocessen, som handlar om att komma åt systemresurser i den ordning som bestäms av programmet, representeras av en absorberande Markov-kedja, vars tillstånd motsvarar användningen av systemresurser - processor, minne och kringutrustning; övergång sannolikheter återspeglar ordningen för tillgång till olika resurser. Tack vare detta presenteras beräkningsprocessen i en form som är bekväm för att analysera dess egenskaper.
En Markov-kedja sägs vara irreducerbar om något tillstånd Sj kan nås från vilket annat tillstånd Si i ett ändligt antal övergångar. I det här fallet sägs alla tillstånd i kretsen kommunicera, och övergångsgrafen är en komponent av stark anslutning. En process som genereras av en ergodisk kedja, som har börjat i ett visst tillstånd, slutar aldrig, utan går sekventiellt från ett tillstånd till ett annat, och hamnar i olika tillstånd med olika frekvenser beroende på övergångssannolikheterna. Därför är det huvudsakliga kännetecknet för en ergodisk kedja
sannolikheten för att processen är i tillstånd Sj, j = 1,..., n, den del av tiden som processen tillbringar i vart och ett av tillstånden. Irreducerbara kretsar används som modeller för systemtillförlitlighet. Faktum är att om en resurs som en process använder mycket ofta misslyckas, kommer funktionaliteten i hela systemet att vara i fara. I ett sådant fall kan duplicering av en sådan kritisk resurs hjälpa till att undvika fel. I detta fall tolkas systemets tillstånd, som skiljer sig i sammansättningen av funktionsduglig och felaktig utrustning, som kretstillstånd, mellan vilka övergångar är förknippade med fel och återställning av enheter och förändringar i anslutningar mellan dem, utförda för att upprätthålla systemets funktionsduglighet. Uppskattningar av egenskaperna hos en irreducerbar krets ger en uppfattning om tillförlitligheten av systemets beteende som helhet. Sådana kretsar kan också vara modeller för interaktion mellan enheter och uppgifter som skickas in för bearbetning.
Exempel på användning
Felservicesystem
En server består av flera block, såsom modem eller nätverkskort, som tar emot förfrågningar från användare om service. Om alla block är upptagna går begäran förlorad. Om ett av blocken accepterar en förfrågan, blir den upptagen till slutet av behandlingen. Låt oss ta antalet obesatta block som stater. Tiden kommer att vara diskret. Låt oss beteckna med α sannolikheten att få en förfrågan. Vi anser också att tjänstgöringstiden också är slumpmässig och består av självständiga fortsättningar, d.v.s. en begäran med sannolikhet β betjänas i ett steg, och med sannolikhet (1 - β) betjänas den efter detta steg som en ny begäran. Detta ger sannolikheten för (1 - β) β för en tvåstegstjänst, (1 - β)2 β för en trestegstjänst, etc. Låt oss överväga ett exempel med 4 enheter som arbetar parallellt. Låt oss skapa en matris med övergångssannolikheter för de valda tillstånden:
M  Det kan noteras att det har en unik ergodisk klass, och därför har systemet p × P = p i klassen sannolikhetsvektorer en unik lösning. Låt oss skriva ner ekvationerna för systemet som gör att vi kan hitta denna lösning:
Det kan noteras att det har en unik ergodisk klass, och därför har systemet p × P = p i klassen sannolikhetsvektorer en unik lösning. Låt oss skriva ner ekvationerna för systemet som gör att vi kan hitta denna lösning:


Nu är uppsättningen av sannolikheter πi känd att i stationärt läge kommer systemet att ha i-block upptagna. Då är en bråkdel av tiden p 4 = C γ 4 /4 alla block i systemet upptagna, systemet svarar inte på förfrågningar. De erhållna resultaten gäller för valfritt antal block. Nu kan du dra nytta av dem: du kan jämföra kostnaderna för ytterligare enheter och minskningen av den tid systemet är fullt upptaget.
Du kan läsa mer om detta exempel i .
Beslutsprocesser med ett ändligt och oändligt antal steg
Betrakta en process där det finns flera övergångssannolikhetsmatriser. För varje ögonblick i tiden beror valet av en eller annan matris på vilket beslut vi fattar. Ovanstående kan förstås med följande exempel. Som ett resultat av jordanalys utvärderar trädgårdsmästaren dess tillstånd med ett av tre siffror: (1) - bra, (2) - tillfredsställande eller (3) - dåligt. Samtidigt märkte trädgårdsmästaren att jordens produktivitet under innevarande år bara beror på dess tillstånd föregående år. Därför kan sannolikheterna för jordövergång utan yttre påverkan från ett tillstånd till ett annat representeras av följande Markov-kedja med matris P1:
L  Det är naturligt att markens produktivitet försämras med tiden. Till exempel, om markens tillstånd förra året var tillfredsställande, kan det i år bara förbli detsamma eller bli dåligt, men kommer inte att bli bra. Trädgårdsmästaren kan dock påverka markens tillstånd och ändra övergångssannolikheterna i matris P1 till motsvarande från matris P2:
Det är naturligt att markens produktivitet försämras med tiden. Till exempel, om markens tillstånd förra året var tillfredsställande, kan det i år bara förbli detsamma eller bli dåligt, men kommer inte att bli bra. Trädgårdsmästaren kan dock påverka markens tillstånd och ändra övergångssannolikheterna i matris P1 till motsvarande från matris P2:
T  Nu kan vi associera varje övergång från en stat till en annan med en viss inkomstfunktion, som definieras som vinst eller förlust under en ettårsperiod. Trädgårdsmästaren kan välja att använda eller inte använda gödningsmedel, detta kommer att avgöra hans slutliga inkomst eller förlust. Låt oss introducera matriserna R1 och R2, som bestämmer inkomstfunktionerna beroende på kostnaden för gödselmedel och jordkvalitet:
Nu kan vi associera varje övergång från en stat till en annan med en viss inkomstfunktion, som definieras som vinst eller förlust under en ettårsperiod. Trädgårdsmästaren kan välja att använda eller inte använda gödningsmedel, detta kommer att avgöra hans slutliga inkomst eller förlust. Låt oss introducera matriserna R1 och R2, som bestämmer inkomstfunktionerna beroende på kostnaden för gödselmedel och jordkvalitet:
N  Slutligen ställs trädgårdsmästaren inför problemet med vilken strategi man ska välja för att maximera den genomsnittliga förväntade inkomsten. Två typer av problem kan övervägas: med ett ändligt och ett oändligt antal steg. I det här fallet kommer trädgårdsmästarens aktivitet definitivt att sluta någon gång. Dessutom löser visualiserare beslutsfattandeproblemet för ett begränsat antal steg. Låt trädgårdsmästaren ha för avsikt att sluta med sitt yrke efter N år. Vår uppgift nu är att bestämma den optimala beteendestrategin för trädgårdsmästaren, det vill säga den strategi som kommer att maximera hans inkomst. Ändligheten i antalet stadier i vårt problem manifesteras i det faktum att trädgårdsmästaren inte bryr sig om vad som kommer att hända med hans jordbruksmark under N+1 år (alla år till och med N är viktiga för honom). Nu kan vi se att i det här fallet förvandlas strategisökningsproblemet till ett dynamiskt programmeringsproblem. Om vi betecknar med fn(i) den maximala genomsnittliga förväntade inkomsten som kan erhållas under stadier från n till och med N, med start från tillståndsnummer i, så är det lätt att härleda den återkommande
Slutligen ställs trädgårdsmästaren inför problemet med vilken strategi man ska välja för att maximera den genomsnittliga förväntade inkomsten. Två typer av problem kan övervägas: med ett ändligt och ett oändligt antal steg. I det här fallet kommer trädgårdsmästarens aktivitet definitivt att sluta någon gång. Dessutom löser visualiserare beslutsfattandeproblemet för ett begränsat antal steg. Låt trädgårdsmästaren ha för avsikt att sluta med sitt yrke efter N år. Vår uppgift nu är att bestämma den optimala beteendestrategin för trädgårdsmästaren, det vill säga den strategi som kommer att maximera hans inkomst. Ändligheten i antalet stadier i vårt problem manifesteras i det faktum att trädgårdsmästaren inte bryr sig om vad som kommer att hända med hans jordbruksmark under N+1 år (alla år till och med N är viktiga för honom). Nu kan vi se att i det här fallet förvandlas strategisökningsproblemet till ett dynamiskt programmeringsproblem. Om vi betecknar med fn(i) den maximala genomsnittliga förväntade inkomsten som kan erhållas under stadier från n till och med N, med start från tillståndsnummer i, så är det lätt att härleda den återkommande
Z  där k är numret på den använda strategin. Denna ekvation är baserad på det faktum att den totala inkomsten rijk + fn+1(j) erhålls som ett resultat av övergången från tillstånd i i steg n till tillstånd j i steg n+1 med sannolikhet pijk.
där k är numret på den använda strategin. Denna ekvation är baserad på det faktum att den totala inkomsten rijk + fn+1(j) erhålls som ett resultat av övergången från tillstånd i i steg n till tillstånd j i steg n+1 med sannolikhet pijk.
Nu kan den optimala lösningen hittas genom att beräkna fn(i) sekventiellt i nedåtgående riktning (n = N...1). Samtidigt kommer det inte att komplicera lösningen av en vektor med initiala sannolikheter i problemformuleringen.
Detta exempel diskuteras också i.
Modellera kombinationer av ord i text
Betrakta en text som består av orden w. Låt oss föreställa oss en process där tillstånden är ord, så att när det är i tillstånd (Si) går systemet till tillstånd (sj) enligt matrisen av övergångssannolikheter. Först och främst är det nödvändigt att "träna" systemet: tillhandahålla en tillräckligt stor text som input för att utvärdera övergångssannolikheterna. Och sedan kan du bygga banor av Markov-kedjan. Att öka den semantiska belastningen för en text som är konstruerad med Markov-kedjealgoritmen är endast möjligt genom att öka ordningen, där tillståndet inte är ett ord, utan sätts med större kraft - par (u, v), trippel (u, v, w) , etc. Dessutom, i kedjorna av första och femte ordningen, kommer det fortfarande att finnas lite mening. Meningen kommer att börja dyka upp när ordningsdimensionen ökar till åtminstone det genomsnittliga antalet ord i en typisk fras i källtexten. Men det är omöjligt att röra sig på det här sättet, eftersom tillväxten av textens semantiska belastning i Markov-kedjor av hög ordning sker mycket långsammare än nedgången i textens unika karaktär. Och en text byggd på Markov-kedjor, till exempel av den trettionde ordningen, kommer fortfarande inte att vara så meningsfull att den är av intresse för en person, men redan ganska lik originaltexten, och antalet tillstånd i en sådan kedja kommer att var fantastisk.
Denna teknik används nu (tyvärr) mycket flitigt på Internet för att skapa webbsidainnehåll. Människor som vill öka trafiken till sin webbplats och förbättra dess sökmotorranking tenderar att lägga så många sökord på sina sidor som möjligt. Men sökmotorer använder algoritmer som kan skilja riktig text från ett osammanhängande virrvarr av sökord. Sedan, för att lura sökmotorer, använder de texter skapade av en generator baserad på en Markov-kedja. Det finns naturligtvis positiva exempel på att använda Markov-kedjor för att arbeta med text, de används för att bestämma författarskap och analysera texters autenticitet.
Markov-kedjor och lotterier
I vissa fall används den probabilistiska modellen för att förutsäga antal i olika lotterier. Tydligen är det ingen mening med att använda Markov-kedjor för att modellera sekvensen av olika cirkulationer. Vad som hände med bollarna i dragningen kommer inte på något sätt att påverka resultatet av nästa dragning, eftersom bollarna efter dragningen samlas in, och i nästa dragning placeras de i lotterifacket i en bestämd ordning. I det här fallet förloras kopplingen till den tidigare cirkulationen. En annan sak är sekvensen av bollar som faller ut inom ett drag. I det här fallet bestäms släppet av nästa boll av tillståndet för lotterimaskinen vid tidpunkten för släppet av den föregående bollen. Således är sekvensen av bollar som tappas i ett drag en Markov-kedja, och en sådan modell kan användas. Det finns en stor svårighet här när man analyserar numeriska lotterier. Lotteriets tillstånd efter att nästa boll faller ut avgör ytterligare händelser, men problemet är att detta tillstånd är okänt för oss. Allt vi vet är att en viss boll ramlade ut. Men när denna boll tappas kan de återstående bollarna ordnas på olika sätt, så att det finns en grupp av ett mycket stort antal tillstånd som motsvarar samma observerade händelse. Därför kan vi bara konstruera en matris av övergångssannolikheter mellan sådana grupper av tillstånd. Dessa sannolikheter är ett genomsnitt av sannolikheterna för övergångar mellan olika individuella tillstånd, vilket naturligtvis minskar effektiviteten av att tillämpa Markov-kedjemodellen på numeriska lotterier.
I likhet med detta fall kan en sådan neural nätverksmodell användas för att förutsäga väder, valutakurser och i samband med andra system där historisk data finns tillgänglig och nyinkommen information kan användas i framtiden. En bra tillämpning i det här fallet, när endast manifestationerna av systemet är kända, men inte de interna (dolda) tillstånden, kan appliceras på dolda Markov-modeller, som diskuteras i detalj i Wikibooks (dolda Markov-modeller).
Markov-kedjor
Introduktion
§ 1. Markovkedja
§ 2. Homogen Markov-kedja. Övergångssannolikheter. Övergångsmatris
§3. Markov jämlikhet
§4. Stationär distribution. Limit Probability Theorem
§5. Bevis för satsen om begränsning av sannolikheter i en Markov-kedja
§6. Tillämpningar av Markov-kedjor
Slutsats
Lista över begagnad litteratur
Introduktion
Ämnet för vårt kursarbete är Markov-kedjan. Markov-kedjor är uppkallade efter den enastående ryske matematikern Andrei Andreevich Markov, som arbetade mycket med slumpmässiga processer och gjorde ett stort bidrag till utvecklingen av detta område. Nyligen kan du höra om användningen av Markov-kedjor inom en mängd olika områden: modern webbteknologi, när du analyserar litterära texter eller till och med när du utvecklar taktik för ett fotbollslag. De som inte vet vad Markov-kedjor är kan ha en känsla av att det är något väldigt komplext och nästan obegripligt.
Nej, det är precis tvärtom. En Markov-kedja är ett av de enklaste fallen av en sekvens av slumpmässiga händelser. Men trots sin enkelhet kan den ofta vara användbar även när man beskriver ganska komplexa fenomen. En Markov-kedja är en sekvens av slumpmässiga händelser där sannolikheten för varje händelse endast beror på den föregående, men inte beror på tidigare händelser.
Innan vi går djupare måste vi överväga några hjälpfrågor som är allmänt kända, men som är absolut nödvändiga för vidare utläggning.
Målet med mitt kursarbete är att närmare studera Markov-kedjors tillämpningar, problemformulering och Markovproblem.
§1. Markov kedja
Låt oss föreställa oss att en sekvens av tester utförs.
Definition. En Markov-kedja är en sekvens av försök, i var och en av vilka en och endast en av följande visas.
oförenliga händelser för hela gruppen, och den villkorade sannolikheten att händelsen kommer att inträffa i den e prövningen, förutsatt att händelsen inträffade i den e prövningen, beror inte på resultaten från tidigare försök.Till exempel, om sekvensen av försök bildar en Markov-kedja och hela gruppen består av fyra inkompatibla händelser
, och det är känt att händelsen dök upp i den sjätte rättegången, så beror den villkorade sannolikheten för att händelsen kommer att inträffa i den sjunde rättegången inte på vilka händelser som dök upp i de första, andra, ..., femte försöken.Observera att oberoende tester är ett specialfall av en Markov-kedja. Faktum är att om testerna är oberoende, beror förekomsten av en viss händelse i något test inte på resultaten av tidigare utförda tester. Härav följer att begreppet en Markovkedja är en generalisering av begreppet oberoende prövningar.
Ofta, när de presenterar teorin om Markov-kedjor, följer de en annan terminologi och talar om ett visst fysiskt system
, som vid varje tidpunkt befinner sig i ett av tillstånden: , och ändrar sitt tillstånd endast vid separata tidpunkter, det vill säga systemet flyttar sig från ett tillstånd till ett annat (till exempel från till ). För Markov-kedjor beror sannolikheten att gå till vilket tillstånd som helst för tillfället endast på vilket tillstånd systemet var i för tillfället och ändras inte eftersom dess tillstånd vid tidigare ögonblick blir kända. Också, i synnerhet, efter testet kan systemet förbli i samma tillstånd ("flytta" från stat till stat).För att illustrera, överväg ett exempel.
Exempel 1. Låt oss föreställa oss att en partikel som ligger på en rät linje rör sig längs denna räta linje under påverkan av slumpmässiga stötar som inträffar i ögonblick
. En partikel kan lokaliseras vid punkter med heltalskoordinater: ; De reflekterande väggarna är placerade vid punkterna. Varje tryck flyttar partikeln till höger med sannolikhet och till vänster med sannolikhet, om inte partikeln är nära en vägg. Om partikeln är nära väggen, flyttar varje tryck den en enhet innanför gapet mellan väggarna. Här ser vi att detta exempel på en partikelvandring är en typisk Markovkedja.Sålunda kallas händelser för systemets tillstånd, och tester kallas förändringar i dess tillstånd.
Låt oss nu definiera en Markov-kedja med hjälp av ny terminologi.
En tidsdiskret Markov-kedja är en krets vars tillstånd ändras vid vissa bestämda tidpunkter.
En kontinuerlig Markov-kedja är en kedja vars tillstånd ändras vid alla slumpmässiga möjliga ögonblick i tiden.
§2. Homogen Markov-kedja. Övergångssannolikheter. Övergångsmatris
Definition. En Markov-kedja sägs vara homogen om den villkorade sannolikheten
(övergång från stat till stat) beror inte på testnumret. Därför istället för att skriva helt enkelt .Exempel 1. En spontan promenad. Låt det vara på en rak linje
vid en punkt med en heltalskoordinat finns en materialpartikel. Vid vissa tidpunkter upplever partikeln stötar. Under påverkan av ett tryck rör sig partikeln med sannolikhet en enhet till höger och med sannolikhet en enhet till vänster. Det är tydligt att positionen (koordinaten) för en partikel efter en stöt beror på var partikeln befann sig efter den omedelbart föregående stöten, och inte beror på hur den rörde sig under påverkan av andra tidigare stötar.Således är en slumpmässig promenad ett exempel på en homogen Markov-kedja med diskret tid.
Liknande artiklar



